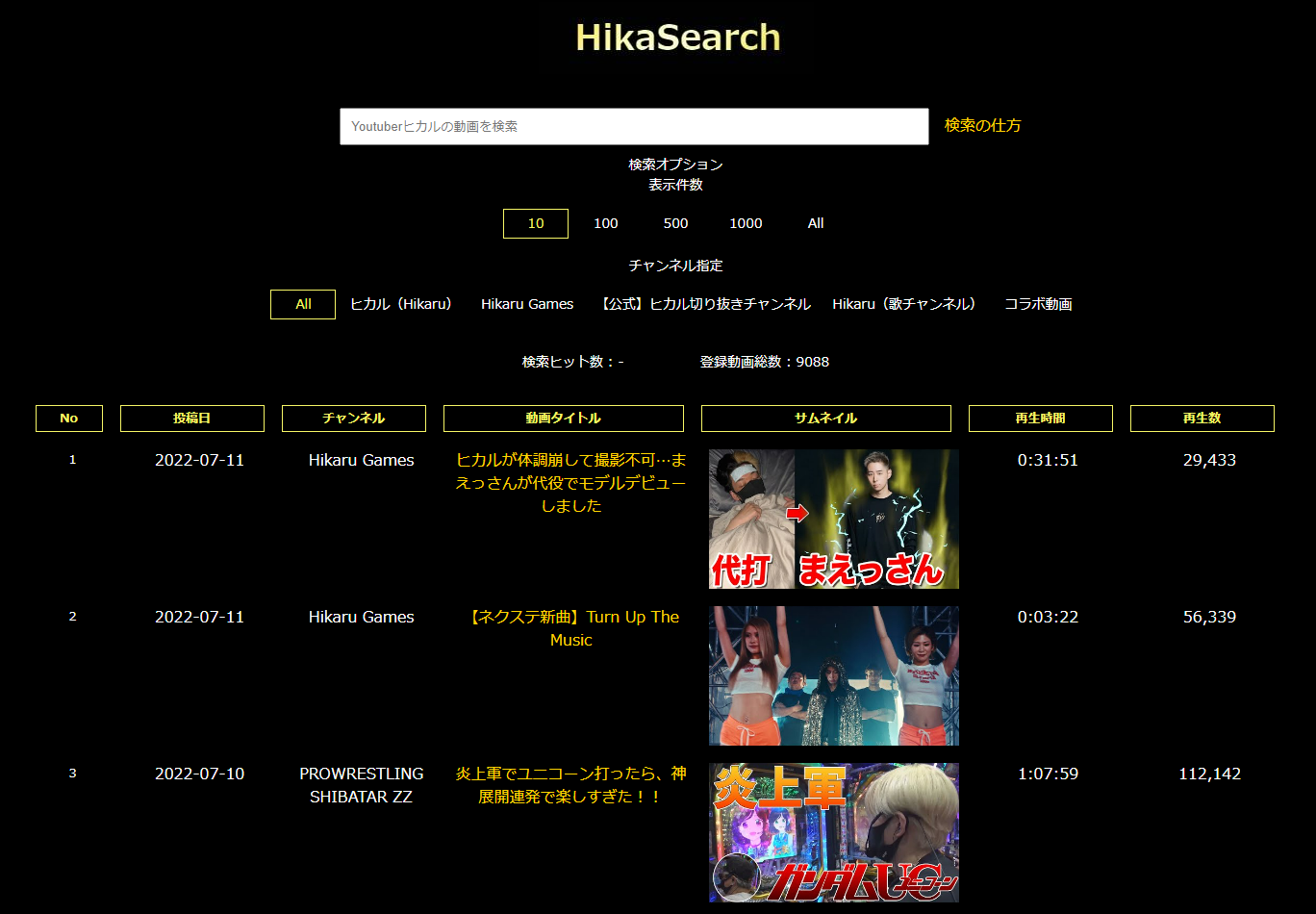
今年の5月にYoutuberヒカルの動画を即時に検索できる「HikaSearch – ヒカサーチ」というWebサービスを公開しまして、初公開から2か月くらい、徐々にアップデートをかけてようやく実装したい機能がだいたい出来てきたかなという感じです。
このサイトを作る中で、当然Youtube APIのことはいっぱい調べました。検索で引っかかるサイトのコードをあれこれ試しては、うまく動かなかったり、取得したいデータが取れなかったりと、色々な知見が得られましたので、Youtube API使って動画の情報を取得したい人の参考になればと思い、動画情報を取得するスクリプトのコードを公開します。
Youtube APIを使う場合の概要
私はAPIを扱うのに慣れてないのもあって、公式サイト見てもなかなか理解できなかったのですが、基本的にどんな感じに動画情報の取得が出来るのかを書きますと、以下の2項目になります。
1.動画のIDを取得する
2.取得した動画IDを使って、動画の詳細情報を取得
この基本的な流れを理解するだけで、この後解説するコードの理解がだいぶしやすくなるんじゃないかと思います。
※動画のIDというのは、下記のようなYoutubeのURLにある、=イコール記号の後の、赤字の部分です
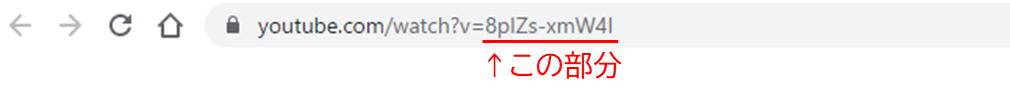
Youtube APIで情報を取得するスクリプトは、Python3系で作成しています。そこまで複雑なことはしていないのですが、なんか動いちゃってて完璧な解説できない部分もあったりしますが、次から説明していきたいと思います。
Youtube動画のIDを取得するコード
それでは動画IDを取得するコードはこちらになります。
Youtube APIの検索(Search)を使っています。
# -*- coding: utf-8 -*-
from apiclient.discovery import build
import json
import datetime
from dateutil.relativedelta import relativedelta
import csv
import time
import os
# API情報
API_KEY = 'xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx'
videos = [] # VideoIDを格納する配列を作成
dt_nowtime = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S') # 現在の時刻を、指定形式で変数に格納
dt_now = datetime.datetime.strptime(dt_nowtime, '%Y-%m-%d %H:%M:%S') # 時刻情報を文字列に変換
#動画のチャンネルID指定、下記ではヒカルの公式の4チャンネルを指定
ListchannelID = ['UCaminwG9MTO4sLYeC3s6udA','UCVpGiJmXoTpjrpkVEAfbpHg','UCvc33FeURfaIN5M8x9wGVjQ', 'UCzVaupa8VNfVXxkYJibizlw']
#Youtube API で問い合わせでVideoIDを取得する関数を定義
def youtube_search(channelID, st, ed):
youtube = build('youtube', 'v3', developerKey=API_KEY)
search_response = youtube.search().list(
channelId=channelID,
part='snippet',
type='video',
maxResults=50,
publishedAfter=st, # '2013-01-01T00:00:00Z',
publishedBefore=ed, # '2014-01-01T00:00:00Z',
pageToken=''
).execute()
for search_result in search_response.get("items", []):
if search_result["id"]["kind"] == "youtube#video":
d = {
'inherentProperties': {
'id': search_result["id"]["videoId"]
}
}
# []で囲って配列に格納しないとCSVで書き込み時にVideoIDがQ,z,r,2,P,u,3,5,n,B,Uとなるので回避のため
videos.append([d['inherentProperties']["id"]])
#VideoIDを取得して配列に格納
#本スクリプトを実行したタイミングから24時間まで遡ってVideoIDを取得
for channelID in ListchannelID:
for i in range(1, 2):
youtube_search(channelID, (dt_now + relativedelta(days=-1)).isoformat()+'Z', dt_now .isoformat()+'Z')
#VideoIDを取得して配列に格納
#期間指定を指定してVideoIDを取得
#for channelID in ListchannelID:
# dt = datetime.datetime(2022, 6, 1, 0, 0) #2022年6月1日から取得
# for i in range(1, 2): # 1,2 だと一か月分取得で 1,13だと12カ月分の取得
# youtube_search(channelID, dt.isoformat()+'Z',
# (dt + relativedelta(months=1)).isoformat()+'Z')
# dt = dt + relativedelta(months=1)
#csvに書き込む
with open('./Hikaru_VideoID_DB.csv', 'a', newline='', encoding='UTF-8') as f: #ファイル開いて
writer = csv.writer(f, delimiter=',') #デミリタを,に指定
writer.writerows(videos) #ここで書き込み
os.system('sort ./Hikaru_VideoID_DB.csv | uniq > ./Hikaru_VideoID_DB.tmp') #CSVにIDの重複があれば削除tempファイルに格納
os.system('cp ./Hikaru_VideoID_DB.tmp ./Hikaru_VideoID_DB.csv') #tmpからcsvに上書きコピースクリプトの大きな流れとしては、下記のようになります。
1.API Keyや現在時間の取得、取得したいチャンネルIDなど、設定値を事前準備
2.Youtube APIで問い合わせてVideoIDを取得する関数を定義
3.関数を利用して、実行したタイミングから24時間まで遡ってVideoIDを取得
4.配列に格納したVideoIDをCSVファイルに書き込む
このコードをcronで定期的に実行することで、毎日更新される動画の情報を自動的に取得するようになってます。
ただ、このVideoIDを取得するこのスクリプト、結構取得に失敗するんですよね……。なので、cronで数回定期実行して、何度かVideoIDを取得して、CSVファイルに追記してます。
何度もCSVファイルに追記するために、CSVファイルに同じVideoIDが重複していくために、最後のos.system関数で、CSVから重複行を削除するためにuniqなどを使ってます。
ちなみにこのスクリプトは、毎日定期実行するのを前提の形としているので、最初のVideoIDのリストを作成した時は、コメントアウトしている50~57行の部分を有効化して、46~48行の部分をコメントアウトしてください。
期間指定してVideoIDを取得するところは、
・53行目のところで開始日時を取得
・54行目のところで開始日時からどのくらいの期間を取得するか
という感じで値を指定して取得していきます。
動画IDから動画の詳細情報を取得するコード
上記のVideoIDを取得したら、そのVideoIDのリストを元に個々の動画の詳細情報を取得します。
こちらはYoutube APIの動画(Videos)を使って取得していきます。
# -*- coding: utf-8 -*-
import urllib.request
import urllib.parse
import json
import csv
import isodate
import datetime
from apiclient.discovery import build
from dateutil.relativedelta import relativedelta
import math
import time
# API情報
API_KEY = 'xxxxxxxxxxxxxxxxxxxxxxxxxxx'
videos = [] # VideoIDを格納する配列
dt_nowtime = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S') # 現在の時刻を、指定形式で変数に格納
dt_now = datetime.datetime.strptime(dt_nowtime, '%Y-%m-%d %H:%M:%S') # 時刻情報を文字列に変換
# CSVファイル読み込み先 パス指定
csvfile = "./Hikaru_VideoID_DB.csv"
nextPageToken = ''
outputs = []
n = 0
with open(csvfile) as f:
for row in csv.reader(f):
d = {'[': None, ']': None, "\'": None}
tbl = str.maketrans(d)
videos.append(str(row).translate(tbl))
splitcnt = math.ceil(len(videos) / 50)
if splitcnt > 1:
newarys = [videos[idx: idx + 50]
for idx in range(0, len(videos), 50)]
else:
newarys = videos
for videos in newarys:
# videoメソッドで動画情報取得
param = {
'part': 'id,snippet,contentDetails,player,recordingDetails,statistics,status,topicDetails',
'id': ",".join(videos), # VideoIDリストが50件以上の場合はこちらを使用する。
# 'id': videos, # VideoIDリストが49件以下の場合はこちらを使用する。
'key': API_KEY
}
target_url = 'https://www.googleapis.com/youtube/v3/videos?' + \
(urllib.parse.urlencode(param))
req = urllib.request.Request(target_url)
try:
with urllib.request.urlopen(req) as res:
videos_body = json.load(res)
# CSV書き込み用データ準備
for item in videos_body['items']:
# 値が存在しない場合ブランク
publishedAt = item['snippet']['publishedAt'] if 'publishedAt' in item['snippet'] else ''
title = item['snippet']['title'] if 'title' in item['snippet'] else ''
url = 'https://www.youtube.com/watch?v=' + \
item['id'] if 'id' in item else ''
thumbnail_url = item['snippet']['thumbnails']['high']['url'] if 'thumbnails' in item['snippet'] else ''
channelTitle = item['snippet']['channelTitle'] if 'channelTitle' in item['snippet'] else ''
# tags = item['snippet']['tags'] if 'tags' in item['snippet'] else ''
if 'tags' in item['snippet']:
d = {'[': '#', ']': None, "\'": None,
'\"': None, ',': ' #', ' ': None}
tbl = str.maketrans(d)
tags = str(item['snippet']['tags']).translate(tbl)
else:
tags = ""
if 'duration' in item['contentDetails']:
# durationを時分秒へ変換
duration = isodate.parse_duration(
item['contentDetails']['duration'])
else:
duration = ''
viewCount = item['statistics']['viewCount'] if 'viewCount' in item['statistics'] else 0
likeCount = item['statistics']['likeCount'] if 'likeCount' in item['statistics'] else 0
commentCount = item['statistics']['commentCount'] if 'commentCount' in item['statistics'] else 0
outputs.append([publishedAt, channelTitle, title, thumbnail_url,
duration, viewCount, url, likeCount, commentCount, tags])
except urllib.error.HTTPError as err:
print(err)
# CSV書き込み
with open('./DB/'+dt_now.strftime('%Y-%m-%d_%H%M%S') + '_Hikaru_VideoInfo_DB.csv', 'w', newline='', encoding='UTF-8') as f: # 上書き
writer = csv.writer(f)
writer.writerows(outputs)
with open('./Hikaru_VideoInfo_DB.csv', 'w', newline='', encoding='UTF-8') as f: # 上書き
writer = csv.writer(f)
writer.writerows(outputs)
この動画情報を取得するスクリプトですが、大きな流れとしては以下のようになります。
1.API Keyや現在時間の取得、取得したいチャンネルIDなど、設定値を事前準備
2.VideoIDリストのCSVファイルを配列に読み込む
3.VideoIDを元に、個々の動画の詳細情報を取得する
4.取得した動画の詳細情報から、必要なものだけを抜き出す
5.動画情報をCSVファイルに書き込む
このコードもcronで1日に一回定期実行しています。こちらの動画情報を取得するスクリプトの場合は、VideoIDの取得する時と違って取りこぼしはおきないようです。
現在ヒカル関連動画のリストは約9000個を超えているのですが、この9000個の動画情報を1日一回取得しています。スクリプトを実行すると、完了まで2~3分かかります。9000個くらい一気に取得しても、今のところ取りこぼしている雰囲気はないので、一度に大量な動画情報を取得できるみたいです。
たまに手動で実行することもあるのですが、9000個の情報取得を2~3回実行しても、APIの取得制限に引っかかることはないです。Searchのほうはすぐ制限掛かっちゃうんですけどね……。こんな違いもあります。
尚、44行目と45行目のコメントに
「VideoIDリストが49件以下の場合はこちらを使用する。」
「VideoIDリストが50件以上の場合はこちらを使用する。」
と書いてあると思うんですが、これも正確には動作を確認出来てないのですが、読み込むVideoIDリストに記載してあるVideoIDの数が49個以下と50個以上でコメントアウトの部分を使い分ける必要がありますので、ご注意ください。
Youtube APIを使ってみて
今回初めてYoutube APIを使用してみたのですが、色々クセがあるところが分かりました。ネットで公開されているサンプルをひとつひとつ試して、自分が作りたい動きをさせるのにはまーまー時間かかりましたが、約一か月程度で完成できたので、なかなかスピード感ある開発が出来たと思ってます。
まだまだ効率の良いプログラムが書けると思うのですが、今回はスピード重視ということで、今後もコードを整理出来たらと思ってます。
Youtube APIを使って何かしようと考えてる人がいれば、ぜひこの記事を参考にしてみてください!
もしこのスクリプトで質問などあれば、お気軽にTwitterなどでご連絡ください!